Web Scraping Basics
Web scraping involves downloading and then parsing web pages, which means you need to have some basic understanding of how HTML and CSS work.
HTML
HTML is made up of elements. Elements are made of tags.
Most elements have an opening tag, some content, and then a closing tag.
<tagname>some content goes here</tagname>
Here's a paragraph tag:
<p>I'm a paragraph</p>
Different tags are used for different types of content:
p: paragraph of texta: a linkul: unordered (bulleted) listli: a list itemstrong: important texth1: A large headlineh2: A smaller headlinediv: a widely used tag to signify a division or section of content
Attributes
Tags can also have attributes. These are key/value pairs that declare extra information about the tag. An attribute looks like this:
<tagname attributename="value">content</tagname>
Some attributes can be applied to any tag. The two most important ones (for our purposes) are id and class.
The id attribute gives a unique id to a tag. There can only by one tag with any given id.
<p id="the-most-important-paragraph">This is the most important paragraph.</p>
The class attribute indicates a user-defined category for a tag. Many tags (including different types of tags) can share the same class name.
<p class="sort-of-important">I'm a sort of important paragraph</p>
<p class="sort-of-important">I'm also a sort of important paragraph</p>
<div class="sort-of-important">I'm another a sort of important thing</div>
Some attributes are specific to certain tags.
The a tag, for example, requires an href attribute that indicates where the browser should navigate to when someone clicks on it.
<a href="http://whitehouse.gov">don't click here</a>
Some elements DON'T have a closing tag. The image tag, for example, doesn't have a closing tag but requires the src attribute to be set:
<img src="lolcapitalism.jpg">
A Barebones Webpage
All HTML documents contain the following tags:
html: Surrounds the entire documenthead: A tag that doesn't render to the page but contains important links to style sheets and the title tagtitle: The title of the pagebody: Surrounds the body of the page
HTML elements are nested within other elements.
For example, here's a complete HTML document:
<html>
<head>
<title>My Cool Website</title>
</head>
<body>
<div>
<h1>A Communisty Manifesto</h1>
<p>
Many <strong>spectres</strong> are haunting Europe.
Here are some of them:
</p>
<ul>
<li>The first spectre</li>
<li>The second spectre</li>
<li>The third spectre</li>
</ul>
<img src="so-many-spectres.jpg">
<p>Keep reading to find out all of the spectres currently haunting Europe!</p>
</div>
</body>
</html>
Note the indentations. These are completely optional (the machine doesn't care if you indent or not), but it's good practice to always indent elements inside of other elements because it helps show the structure of the document.
CSS
CSS stands for "cascading stylesheet".
CSS determines the look of a website, both positioning elements on the screen and giving them visual attributes like color, or font size.
Many of the particulars of CSS styling are irrelevant for this guide. What matters for us is the syntax that determines how styles are applied, because it provides a handy system for isolating and extracting particular elements from an HTML document.
A css style is made of a selector followed by rules. We don't care about the rules, just the selector. Here is a bit of fake CSS:
selector { /* the bit before the squiqqly is called the "selector" */
rule: some rule here; /* these are rules, we don't care about them */
another-rule: more rules; /* more rules */
}
The selector determines what gets styled. Selectors can be used to target all instances of a particular tag, elements with particular classes or ids, and other more complex rules.
You can target every instance of a tag by referencing the name of the tag:
p {
color: red;
}
You can also give style to tags that have particular ids or classes.
Select classes by preceding the class name with a period . character. For example, select all tags with the "proletariat" class:
.proletariate {
background-color: red;
}
Select ids by preceding the id name with a hashtag # character.
#the-manifesto {
border: 10px solid orange;
}
You can also select elements that are inside other elements, by first writing the parent element, then a space, then the child element.
For example, this selects a tags that are INSIDE p tags:
p a {
background-color: black;
}
You can also do this with classes and ids. This selects span tags found inside elements with the author class.
.author span {
color: pink;
}
You can use the comma to get multiple selectors. The following grabs h1 tags and h2 tags:
h1, h2 {
color: orange;
}
Here's a full list of css selectors.
Web Scraping
Although it's possible to use Python's standard library to scrape the web, I find it a bit easier to use community-developed tools built for the purpose. There are a number of these available and all have merits. For the sake of this tutorial we will use two external libraries: requests which makes performing network requests easier, and beautifulsoup, which parses html.
Installing Python packages with pip
Since these tools don't come pre-packaged with Python, we need to install them using Python's package manager, pip.
You can either install packages globally on your system, for just your user, or you can set up a per-project "virtual environment". For the sake of starting quickly, we'll be using the easiest option, which installs into your home folder.
First, let's install the requests library. Open the terminal and type:
pip3 install requests
Then, install beautifulsoup (note that the package name is "beautifulsoup4"):
pip3 install beautifulsoup4
These packages will now be available to all your python scripts.
Basics
The basic workflow for most scraping projects is:
- Download html from a url
- Identify what elements you are interested in extracting
- Extract text or attributes via CSS selectors
To start, you must import the requests library, and then use requests.get to retrieve a web page.
# import the requests library
import requests
# import beautifulsoup
from bs4 import BeautifulSoup
# get the front page of the New York Times
response = requests.get('https://nytimes.com/')
# create a beautifulsoup object using the html
soup = BeautifulSoup(response.text)
Now you can use css selectors to pull out certain elements with the select method, which takes a css selector and returns a list of matching elements.
# get a list of all h1 tags based on css selectors
titles = soup.select("h1")
for t in titles:
print(t.text)
The select method can take any css selector. For example:
all_header_tags = soup.select("h1,h2,h3,h4,h5,h6")
links_with_a_classname = soup.select("a.cool-link")
images_inside_divs_inside_main = soup.select("#main div img")
soup.select returns a list. If you just want a single element, you can either get the first element of the returned list, or use the select_one method:
# the first headline
title = soup.select("h1")[0]
# or use soup.select_one
title = soup.select_one("h1")
You can extract text with from elements using the text keyword, or you can extract html attributes which are automatically mapped to a python dictionary. For example:
# get all urls linked to from the page
links = soup.select('a')
for link in links:
print(link.get("href"))
# get all image urls
images = soup.select('img')
for image in images:
print(image.get("src"))
Nested elements
You can also call select on individual elements, rather than the entire html page. For example, imagine the following HTML structure:
<article>
<h2>Near the Wild Heart</h2>
<span>Clarice Lispector</span>
</article>
<article>
<h2>The Man Without Qualities</h2>
<span class="author">Robert Musil</span>
</article>
<article>
<h2>Orlando</h2>
<span class="author">Virginia Woolf</span>
</article>
To extract titles and authors, you might do something like this:
books = soup.select('article')
for article in articles:
title = article.select_one('h2').text
author = article.select_one('.author').text
print(title, author)
The Web Inspector
Every site you scrape will be a bit different, and it can sometimes be difficult to figure out what css selectors to use. You may need to experiment to figure out what works. Fortunately, there's a tool built into most browsers that can help you with this, called the "web inspector".
To use the inspector, simply right click on the element that you are interested in, and select "inspect" (or "inspect element").
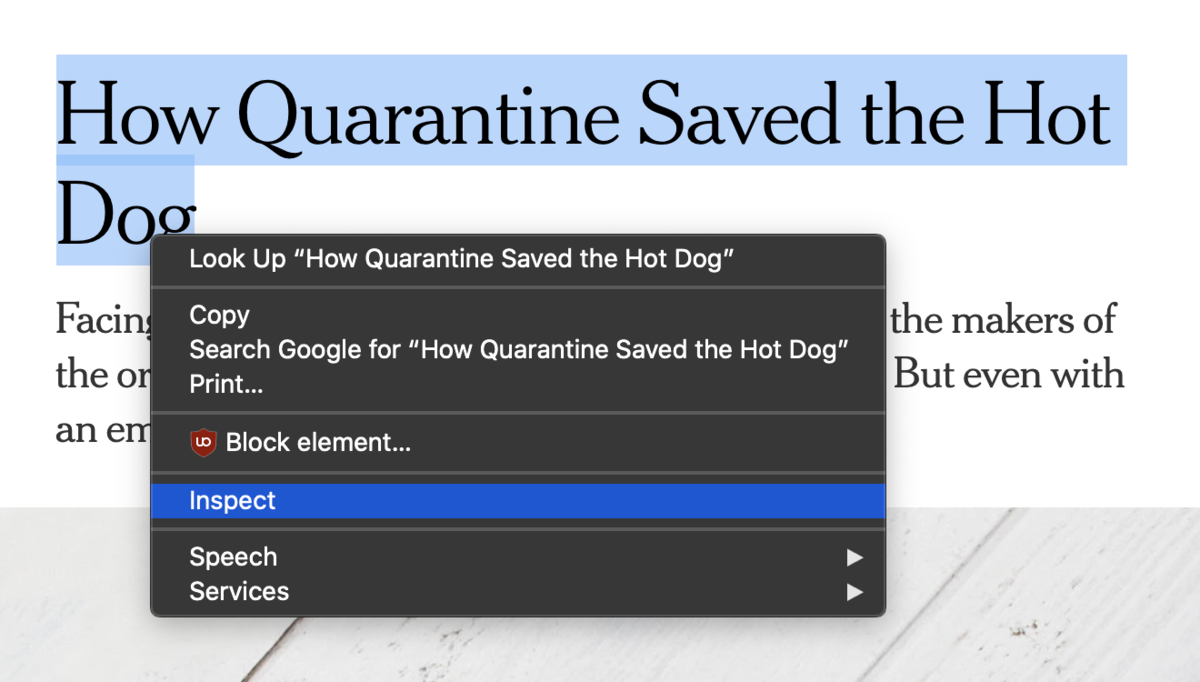
This will open a new panel in your browser that shows the source code of the page, highlighting the element you selected. You can mouse over other elements in the source code to see which ones they correspond to on the page.

Examples
Here's a quick example that grabs the total number of job listings in every category on craigslist (I go over this one in the video at the top of the page):
from bs4 import BeautifulSoup
import requests
base_url = "https://newyork.craigslist.org"
r = requests.get(base_url)
soup = BeautifulSoup(r.text, "html.parser")
job_cats = soup.select(".jobs .cats a")
for job in job_cats:
url = job.get("href")
name = job.text.strip()
full_url = base_url + url
r = requests.get(full_url)
soup = BeautifulSoup(r.text, "html.parser")
total = soup.select_one(".totalcount").text.strip()
print(name, total)
This example gets the full listings titles for every job in a particular category:
from bs4 import BeautifulSoup
import requests
import time
def get_page(url, start):
params = {"s": start}
r = requests.get(url, params=params)
soup = BeautifulSoup(r.text, "html.parser")
titles = soup.select(".result-title")
output = []
for item in titles:
output.append(item.text.strip())
# or
# output = [i.text.strip() for i in titles]
return output
url = "https://newyork.craigslist.org/search/csr"
start = 0
while True:
results = get_page(url, start)
if len(results) == 0:
break
for r in results:
print(r)
start += 120
time.sleep(1)
Problems
The most common problem you'll run into when using this method is that the elements you see in your browser somehow don't appear when you try to parse the html with beautifulsoup. There are two reasons why this might be the case.
- The content you see in the browser is being loaded in with Javascript, after the initial HTML is loaded. This is very common in 2020, and we'll cover this case in a later section.
- The server has detected that you are running a script and has decided to block your access. Depending on the site you are trying to scrape, you may be able to circumvent this by adding a user-agent string to your request.
Pagination
Coming soon